Word Embedding
两种方法
Count-based
- word frequency and co-occurrence matrix
Context-based
词向量常用方法
Distributed representaion:包含信息多
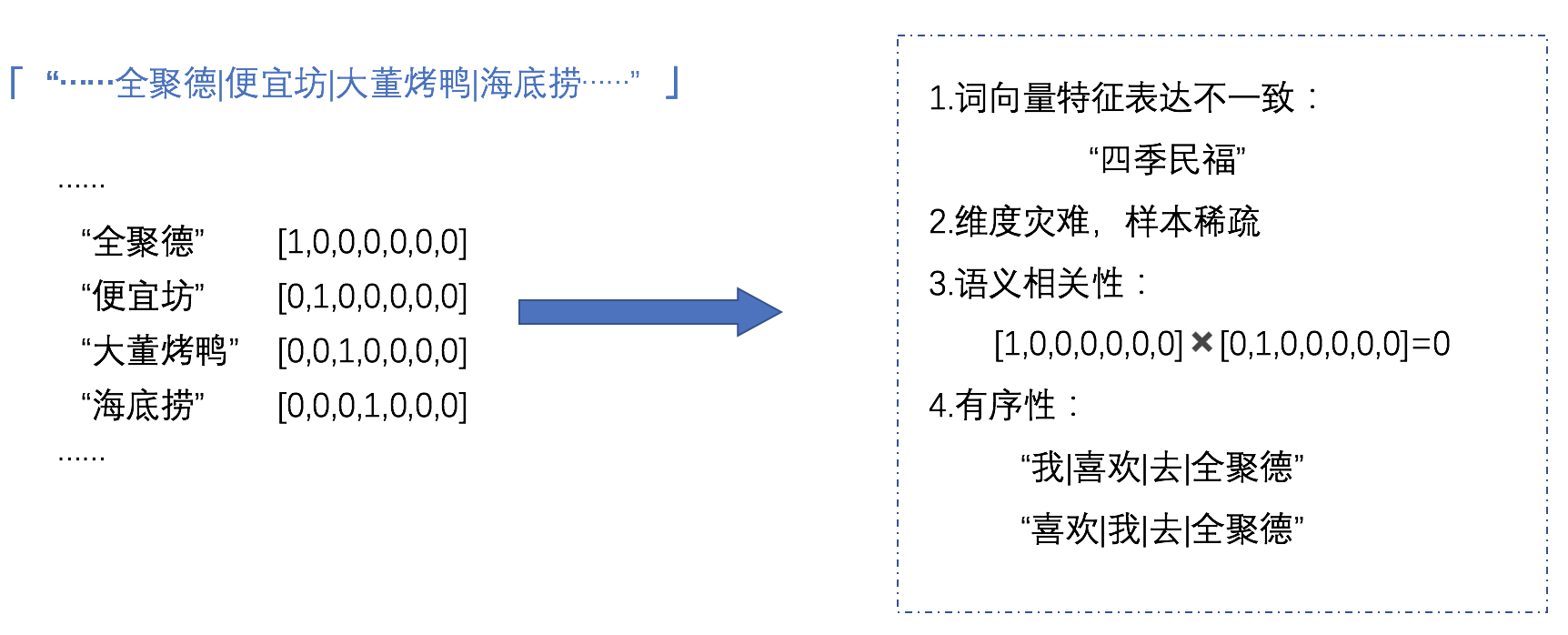
[[One-hot Encoding]] 维度灾难,样本稀疏
统计语言模型:通过统计词频计算一个句子在文本中出现的概率,以此确定哪个词序列的可能行更大。
[[Markov]]假设 n-gram 模型
泛化能力差、模型计算复杂度高、没有解决文本本身的表征问题
[[NNLM]] 利用神经网络求解出每个词语的 Word Embedding
[[Word2Vec]] 考虑文本的上下文环境
[[GloVe]] svd 矩阵分解和 [[Word2Vec]] 上下文思想
Conxtextualized Word Embedding 每一个 word token 都给一个 embedding
[[ELMo]]
[[GPT]] 单向语言模型,生成式任务
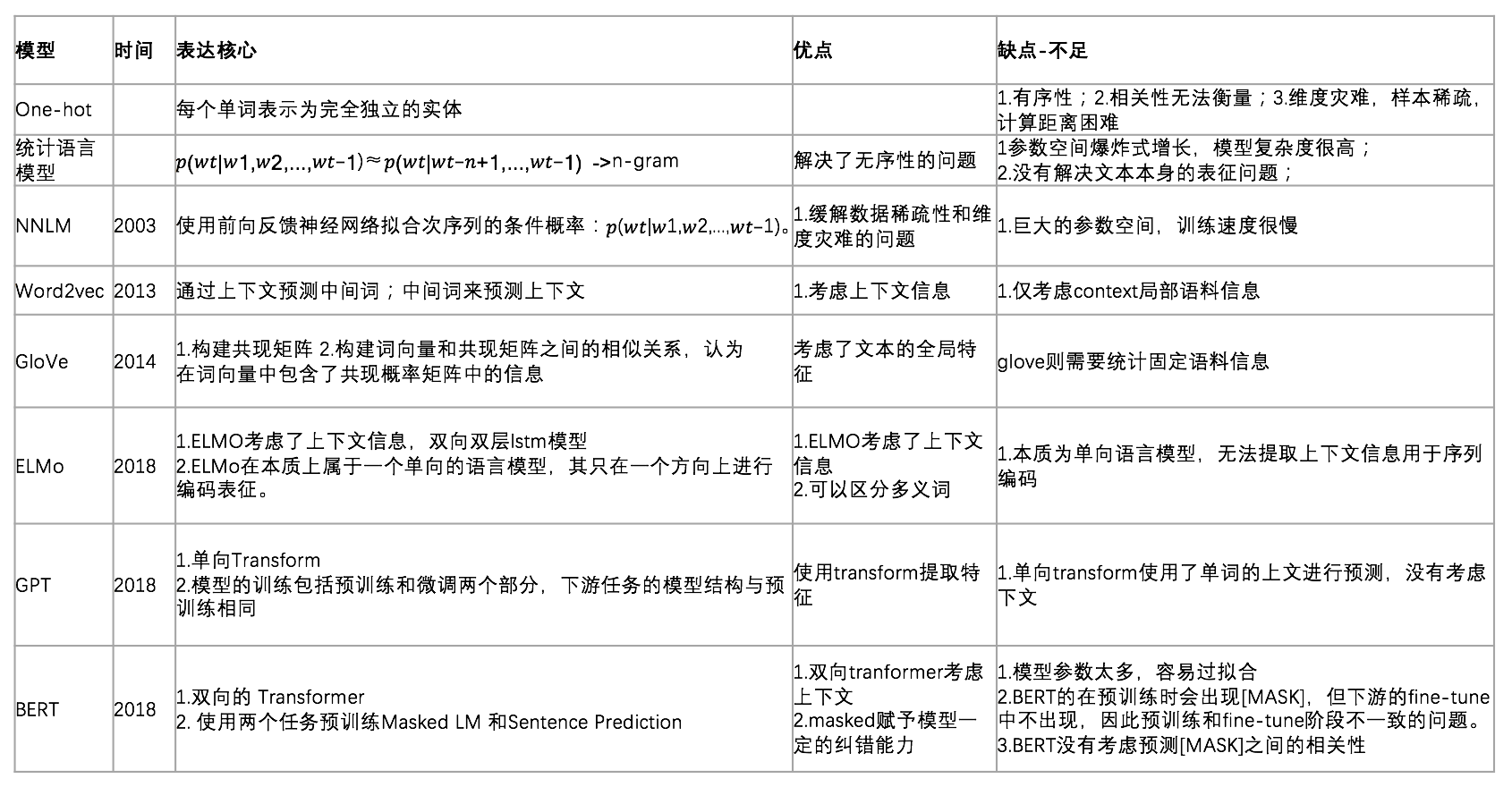
常见 emebdding 方法对比